
Category: Articles
Word Cloud of RSA Meeting Request Emails
I wanted to see what the “trend words” were in the PR emails being sent to press leading up to the RSA conference. Using TagCrowd I was able to copy and paste the subjects and bodies of all emails sent to the “press list” for RSA 2014.
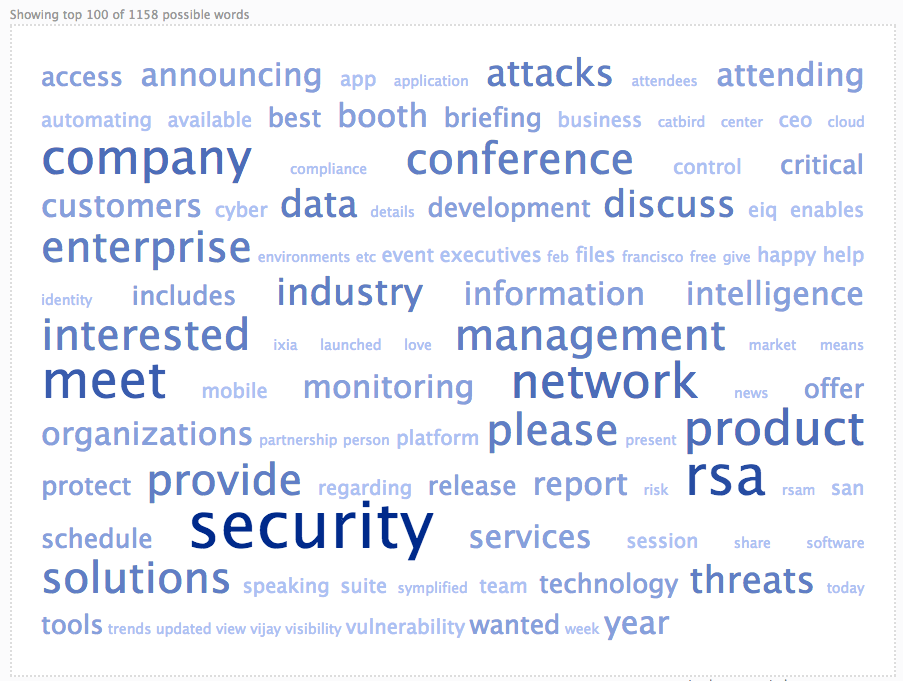
As you can see in Figure 1, the top 5 words used in the PR email blasts are RSA (28), meeting (15), conference (9), request (7), and security (5).
Figure 1 – Email Subject Trend Words

The top 5 words in in the email body, as depicted in Figure 2, are security (108), RSA (63), meet (60), product (47), and a tie between network (40) and company (40).
Figure 2 – Email Body Trend Words
Not entirely useful, but interesting nonetheless 🙂
AWS Tips I Wish I’d Known Before I Started
 I saw this bog post making the “Twitter rounds” yesterday but didn’t really stop to read it over. This morning, over my morning coffee and donut (I rewarded myself with a donut having stepped in dog shit in my bare feet this morning), I sat down and read through the post in its entirety.
I saw this bog post making the “Twitter rounds” yesterday but didn’t really stop to read it over. This morning, over my morning coffee and donut (I rewarded myself with a donut having stepped in dog shit in my bare feet this morning), I sat down and read through the post in its entirety.
Rich Adams nails many of the issues that people fumble through when first starting on AWS. Here are some highlights (I could have quoted many many more) that I completely agree with:
If you need to interact with AWS, use the SDK for your language.
Don’t try to roll your own, I did this at first as I only needed a simple upload to S3, but then you add more services and it’s just an all around bad idea. The AWS SDKs are well written, handle authentication automatically, handle retry logic, and they’re maintained and iterated on by Amazon. Also, if you use EC2 IAM roles (which you absolutely should, more on this later) then the SDK will automatically grab the correct credentials for you.
Have tools to view application logs.
You should have an admin tool, syslog viewer, or something that allows you to view current real-time log info without needing to SSH into a running instance. If you have centralized logging (which you really should), then you just want to be sure you can read the logs there without needing to use SSH. Needing to SSH into a running application instance to view logs is going to become problematic.
Servers are ephemeral, you don’t care about them. You only care about the service as a whole.
If a single server dies, it should be of no big concern to you. This is where the real benefit of AWS comes in compared to using physical servers yourself. Normally if a physical server dies, there’s panic. With AWS, you don’t care, because auto-scaling will give you a fresh new instance soon anyway. Netflix have taken this several steps further with their simian army, where they have things like Chaos Monkey, which will kill random instances in production (they also have Chaos Gorilla to kill AZs and I’ve heard rumour of a Chaos Kong to kill regions…). The point is that servers will fail, but this shouldn’t matter in your application.
Automate everything.
This is more of general operations advice than AWS specific, but everything needs to be automated. Recovery, deployment, failover, etc. Package and OS updates should be managed by something, whether it’s just a bash script, or Chef/Puppet, etc. You shouldn’t have to care about this stuff. As mentioned earlier, you should also make sure to disable SSH access, as this will pretty quickly highlight any part of your process that isn’t automated. Remember the key phrase from earlier, if you have to SSH into your servers, then your automation has failed.
Setup granular billing alerts.
You should always have at least one billing alert setup, but that will only tell you on a monthly basis once you’ve exceeded your allowance. If you want to catch runaway billing early, you need a more fine grained approach. The way I do it is to set up an alert for my expected usage each week. So the first week’s alert for say $1,000, the second for $2,000, third for $3,000, etc. If the week-2 alarm goes off before the 14th/15th of the month, then I know something is probably going wrong. For even more fine-grained control, you can set this up for each individual service, that way you instantly know which service is causing the problem. This could be useful if your usage on one service is quite steady month-to-month, but another is more erratic. Have the individual weekly alerts for the steady one, but just an overall one for the more erratic one. If everything is steady, then this is probably overkill, as looking at CloudWatch will quickly tell you which service is the one causing the problem.
Use tags!
Pretty much everything can be given tags, use them! They’re great for organising things, make it easier to search and group things up. You can also use them to trigger certain behaviour on your instances, for example a tag of env=debug could put your application into debug mode when it deploys, etc.
Lock down your security groups.
Don’t use 0.0.0.0/0 if you can help it, make sure to use specific rules to restrict access to your instances. For example, if your instances are behind an ELB, you should set your security groups to only allow traffic from the ELBs, rather than from 0.0.0.0/0. You can do that by entering “amazon-elb/amazon-elb-sg” as the CIDR (it should auto-complete for you). If you need to allow some of your other instances access to certain ports, don’t use their IP, but specify their security group identifier instead (just start typing “sg-” and it should auto-complete for you).
Read the full list here: http://wblinks.com/notes/aws-tips-i-wish-id-known-before-i-started/
Job Search Progress – Week 2
The data from the first week of job searching was so popular that I thought I’d post the statistics for Week 2.
Figure 1 – Daily Distribution of Meetings
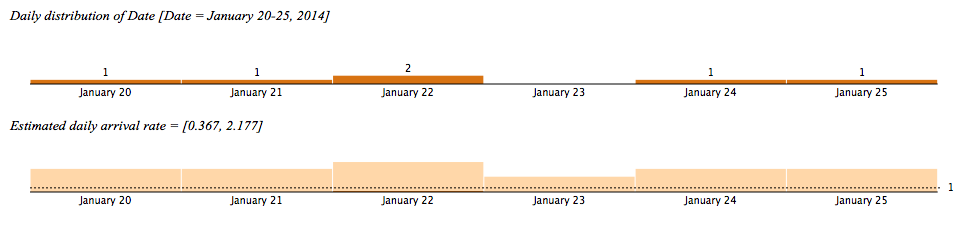
Figure 2 – Date, Time, and Company Distribution
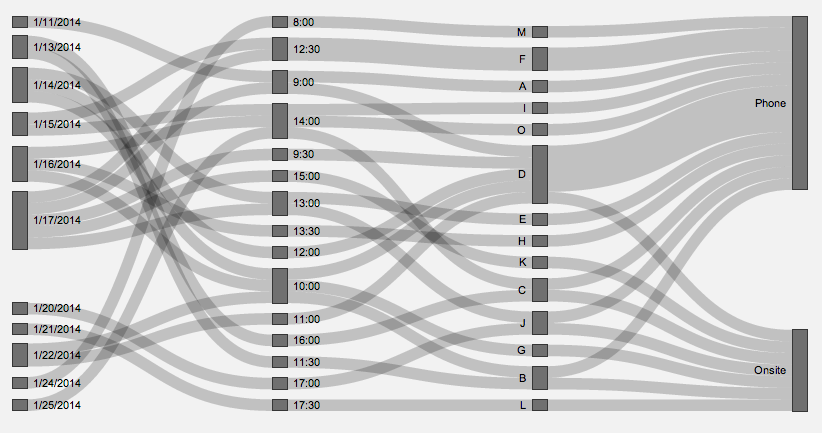
Figure 3 – Distribution of Meeting Duration (in minutes)
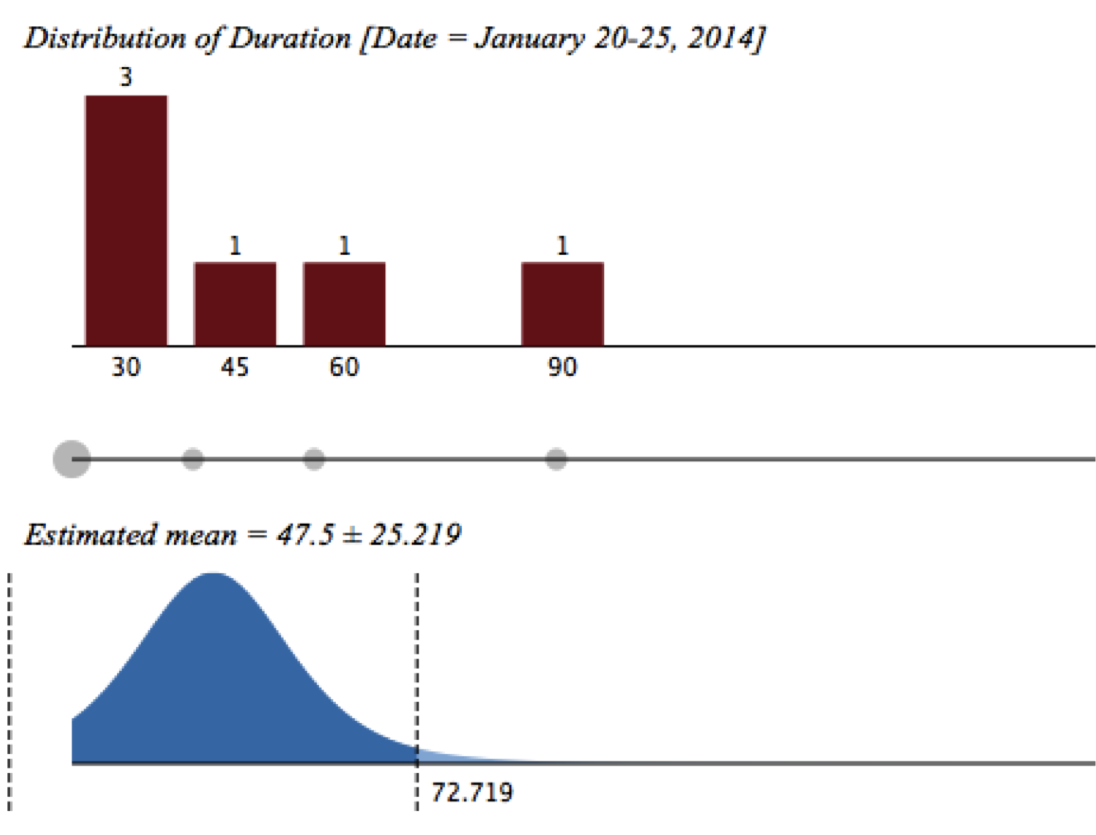
Figure 4 – Distribution of Meeting Type (by date)
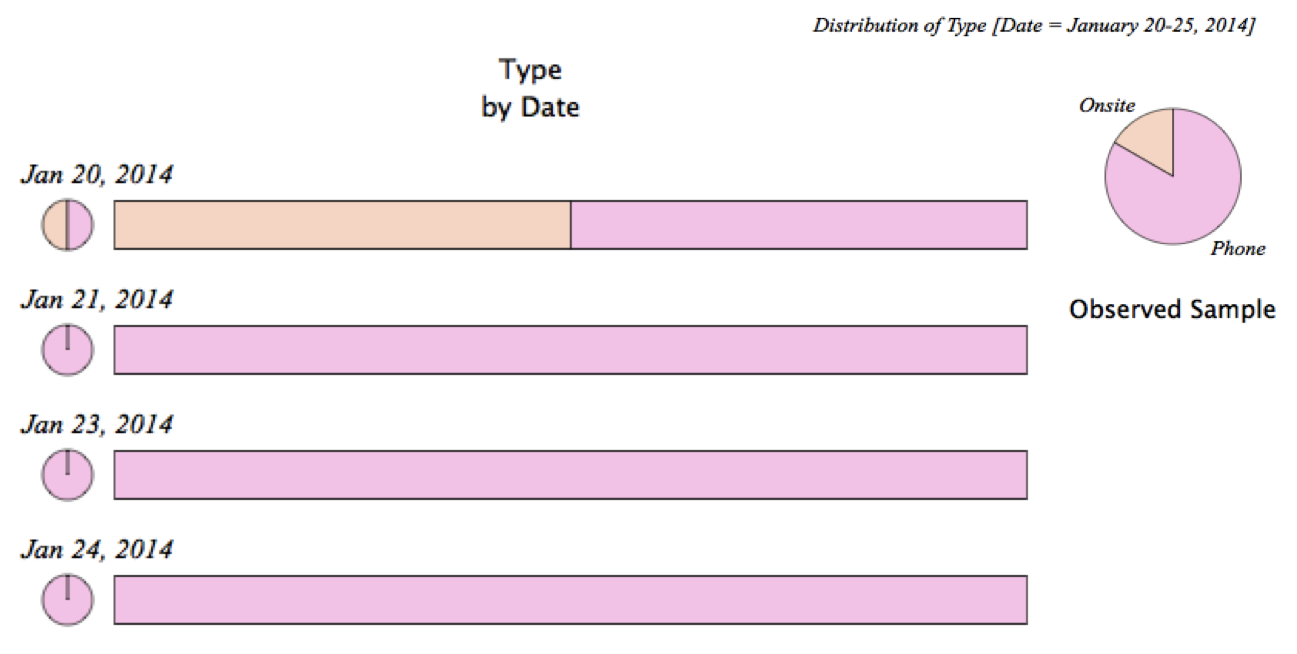
Figure 5 – LinkedIn Search Stats
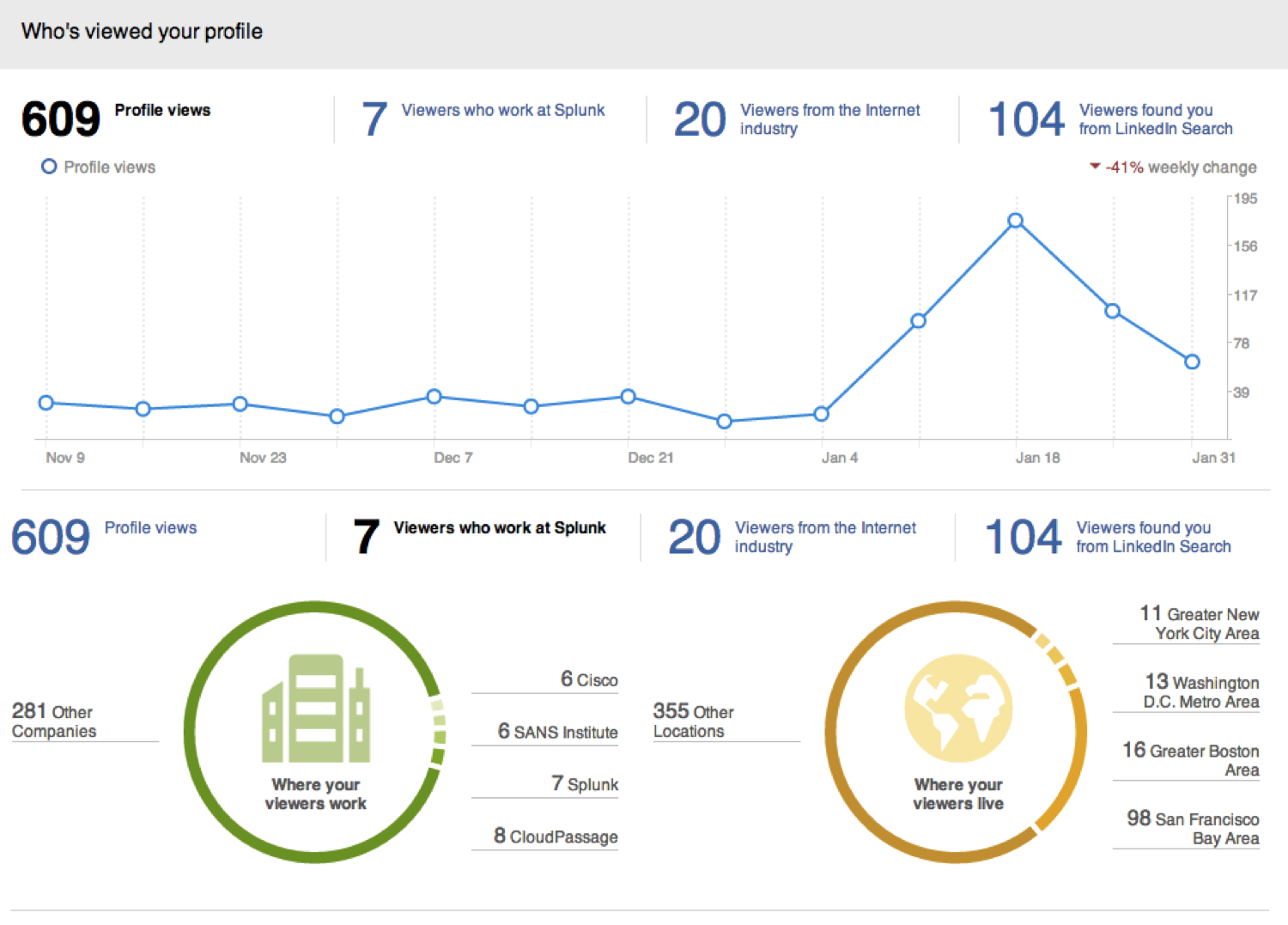
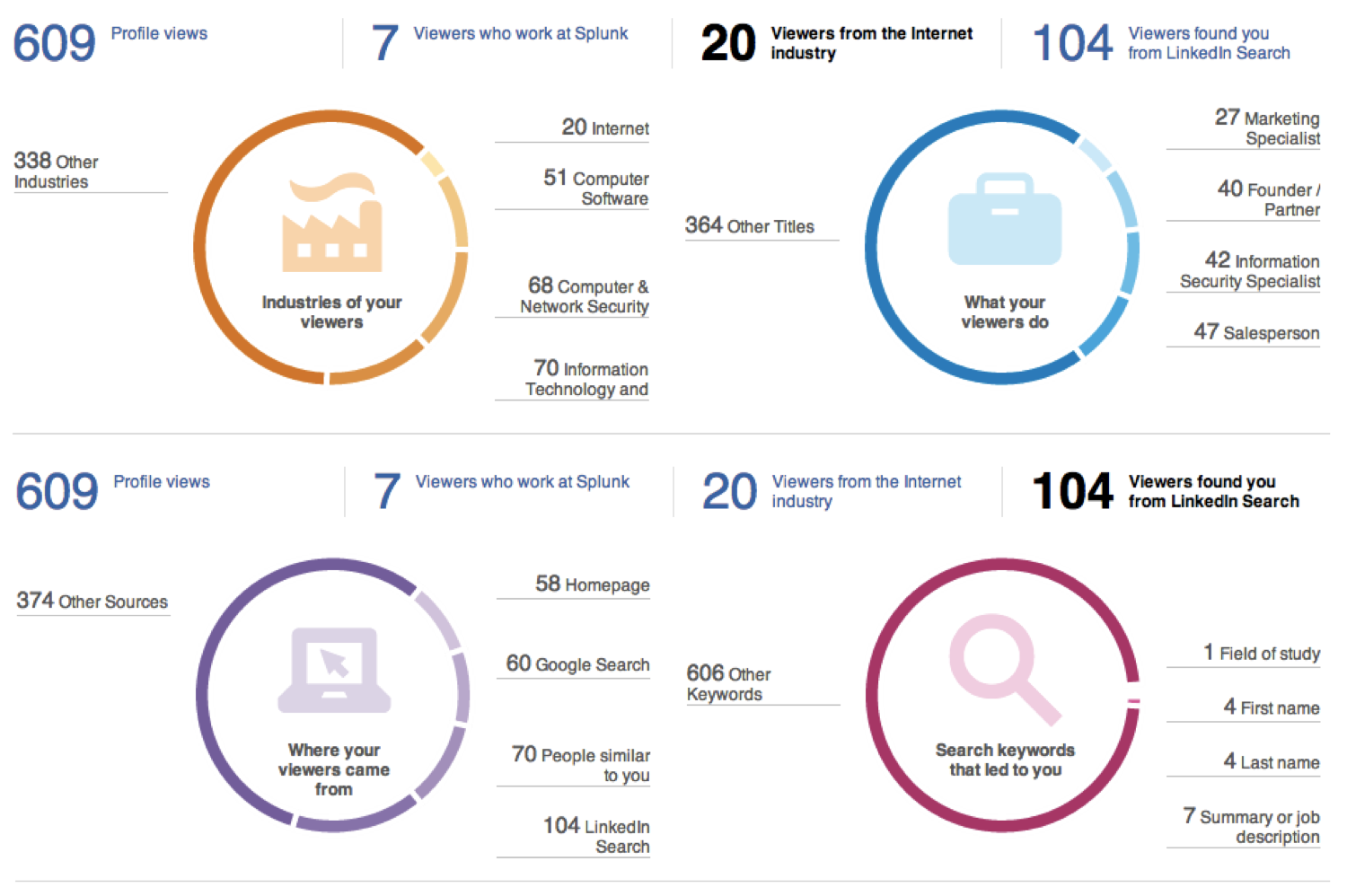
Figure 6 – New LinkedIn Connections
